  
|
2
JClass DataSource Overview
Introduction
The Data Model's Highlights
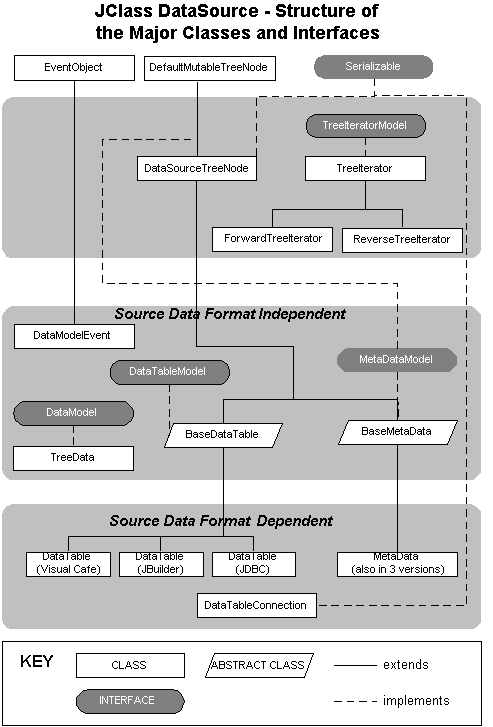
JClass DataSource's Main Classes and Interfaces
The Data "Control" Components
Use of Customizers to Specify the Connection to the JDBC
2.1 Introduction
JClass DataSource has classes and methods that retrieve, organize, and store data items. You can use it with or without JClass HiGrid to interface both to databases and to unbound data sources. With it, you can connect to any type of data source that has a JDBC driver. Its functionality also includes the ability to connect to databases that have JDBC-ODBC driver support, and even to computed data produced by another application. This application may be retrieving information from any source, or producing the data itself. You can structure your design to provide top-level information and as many sub-levels as you deem necessary. You can provide your own visual component, or you can use JClass HiGrid as an easy and functional way of providing end-users with a tool that they can use to display, navigate through, and modify retrieved data. Because you have structured the data hierarchically, end-users are able to expand or collapse their view of the sub-levels.
A group of data bound components are included with JClass DataSource.You can use JClass DataSource to maintain multiple views of the data. For instance, you might provide your users with a HiGrid to make it easy for them to scroll through many records quickly and at the same time provide them with a form containing data-bound components that replicate the fields in the active row of the grid. The information on this form might correspond to one of the sub-levels in the grid - you do not have to bind the components to the root level.
You control whether edits can be made both in the form and in the grid.
JClass DataSource provides data binding capabilities for JClass Chart, JClass Field, JClass LiveTable, and JClass HiGrid, thereby multiplying your options for an elegantly designed form.
2.1.1 Define the Structure for the Data
For this introduction to JClass DataSource, we'll start with the case where all the needed information is stored in a single database. After a connection to the database is established, the next thing to do is to specify the "root" table. We are assuming that a number of sub-tables are also going to be defined. These sub-tables may, in turn, have sub-tables. Thus, the data is being modeled as a tree structure, and the highest level table is the root of this tree.
This description of the data is called meta data. The
MetaDataclass, based on aMetaDataModel, is used to capture this hierarchical design. ThisMetaDataclass connects to a data source through the JDBC or an IDE-specific data-binding mechanism. There is an instance ofMetaDatafor each level in the tree, and each instance ofMetaDatahas a particular query associated with it.MetaDatawill execute that query and cache the results. When used in the context of JClass HiGrid, multiple result sets will be cached. These result sets will be based on the same query but with different parameters. When used in JClass HiGrid, this object will be a node in the meta tree describing the relationships between SQL queries.The root table is treated specially. It is distinguished from dependent tables by having its own constructor. The root table retrieves its data when it is instantiated. Dependent tables can wait until they are accessed before they make calls to the database.
2.1.2 JClass DataSource's Organization
JClass DataSource is really the "Model" in the Model-View-Controller (MVC) architecture. In fact, it is comprised of two more basic models, a meta data model and a data table model. The classes that make up the meta data model cooperate to define methods for describing the way that you want your data structured. The meta data model describes the hierarchical structure of your design and provides a convenient place for storing all the static information about the actual data tables, such as column names and data types. Because the View is separate from the Model, multiple views, even different kinds of views, can all draw their data from the same model. This makes it possible to have a form containing JClass Field components, a JClass LiveTable, and a JClass Chart all presenting data from a connection managed by JClass DataSource. Selecting a different cell in any one of the views and modifying its contents there causes all the mirrored cells in the other views to update themselves, thereby maintaining a consistent view of the data everywhere.
You define the abstract relationship between data tables as a tree. This is the meta data structure, and after it has been designed, you query the database to fill data tables with result sets. The abstract model defines the structure and the specific data items are retrieved using a dynamic bookmark mechanism that is imposed on the result set data tables. At the base level of the class hierarchy, class
MetaDatadescribes a node in theMetaTreestructure and classDataTableholds the actual data for that node. There are different implementations ofMetaDatafor differing data access technologies, therefore there will be a differentMetaDatadefined for the JDBC API and for various IDE-specific data binding solutions. Similarly, there will be differentDataTableclasses depending on the basic data access methodology.
MetaDataandDataTableare concrete subclasses of the abstract classesBaseMetaDataandBaseDataTable.The latter is an abstract implementation of the methods and properties common to various implementations of theDataTablemodel. This class must be extended to concretely implement those methods that it does not, which are all of the methods in the data table abstraction layer. Both these classes are derived fromTreeNodewhich contains a collection of methods for managing tree-structured objects.Interface
MetaDataModeldefines the methods thatBaseMetaDataand its derived classes must implement. This is the interface for the objects that hold the meta data forDataTables. There is oneMetaDataModelfor the root data table, and there can be zero, one, or moreDataTableobjects associated with one meta data object for all subsequent nodes in the meta data model. Thus it is more efficient to store this meta data only once. In terms of JClass DataSource, meta data objects are the nodes of the meta tree. The meta tree, through instances of theMetaDataclasses, describes the hierarchical relations between the meta data nodes.DataTableModelis the interface for data storage for the JClass DataSource data model. It requests data from instances of this table and manipulates that data through this interface. That is, rows can be added, deleted or updated through thisDataTable. To allow sorting of rows and columns, all operations access cell data using unique identifiers for rows and columns.Interface
DataModelis the data interface for the JClass DataSource. An implementation of this interface will be passed to JClass HiGrid or its equivalent. All data for the data source is maintained and manipulated in this data model through its sub-interfaces. This data model requires the implementation of two tree models, one for describing the relationships of the hierarchical data (MetaDataModel) and one for the actual data (DataTable).TreeDatais an implementation ofDataModelfor trees and listener functions. Important methods arerequeryAll,updateAll,add/removeDataModelListener, andenableDataModelEvents. This last method is useful when you are making many changes to the data without having listeners repaint after each individual change. This is a different procedure than usingDataModelEventBEGIN_EVENTSandEND_EVENTS, where events are still sent but the listener receivingBEGIN_EVENTSknows it may choose to disregard the events until it receivesEND_EVENTS.The
DataModelhas one "global" cursor. Commit policies rely on the position of this cursor. This cursor, which is closely related to the bookmark structure, can point anywhere in the data that has been retrieved by JClass DataSource and placed in its data tables. It is found usinggetCurrentGlobalBookmark. Additionally, eachDataTableModelhas its own "current bookmark" or cursor. This cursor is retrieved usinggetCurrentBookmark. If another table is referenced, likely via thegetTablemethod, another completely independent row cursor can be found, again usinggetCurrentBookmark, that can be used to pore over the table using methods such asfirst,last,next,previous,beforeFirst, andafterLast.
2.2 The Data Model's Highlights
The Data Model performs these major functions:
- Connects to a database.
- Defines the structure for the data that is to be retrieved and displayed.
- Specifies the tables and fields to be accessed at each level.
- Sets the commit policy to be used when updating the database.
- Stores result sets from queries.
- Informs the database about pending deletes, updates, and insertions.
- Instructs the database to commit changes at the correct time.
2.2.1 Making a Database Connection with the Help of the JDBC-ODBC Bridge
The Data Bean and The Tree Data Bean components use a JDBC, Java's specification for using data sources, although other data sources, such as ODBC, can be used with the help of a JDBC-ODBC bridge. Both Beans may have multiple connections, and these may be via different database drivers.
If your development system is running on a Windows platform, the needed database drivers must be installed.
- On Windows NT/95/98: choose Start > Settings > Control Panel > ODBC to launch the ODBC data source administrator. On Windows 2000 and XP: choose Start > Settings > Control Panel > Administrative Tools > Data Sources (ODBC) to launch the ODBC data source administrator.
- Click on the User DSN tab and observe the User Data Sources list.
- If the data source you need is not already there, click on the Add button.
- Select the driver for your data source from the list in the Create New Data Source window.
- Use the Configure button to supply extra information specific to the database engine you will be using.
Other environments define different methods for making the low-level connection to a database. Consult the system documentation for your environment for its recommended connection method.
2.3 The Meta Data Model
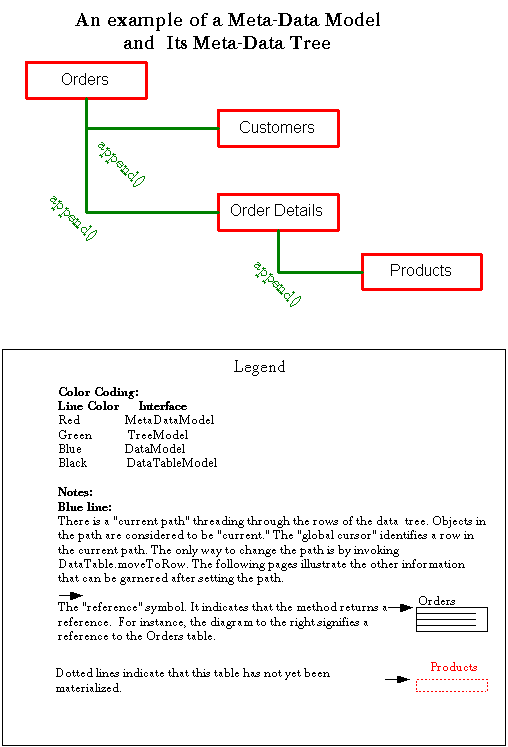
Consider a master-detail design such as that shown in Figure 1. You can create a class that captures this model programmatically or you can describe it using the
JCTreeData's customizer in an IDE.
Figure 1 : A meta data tree containing meta data objects at its nodes.
Both the HTML and PDF on-line versions of this manual are color-coded to distinguish which objects implement the interfaces mentioned in the Legend.
The structure of the meta data tree (green) can be defined after first creating the meta data objects:
//"this" is a class extended from TreeData
// Set up the root level: Orders
BaseMetaData orders = new BaseMetaData(this);
// The rest of the meta data is defined the same way
BaseMetaData customers = new BaseMetaData(this);
BaseMetaData orderDetails = new BaseMetaData(this);
BaseMetaData products = new BaseMetaData(this);The hierarchical relationships among these meta data objects are defined using the
// now add the meta data objects to the tree toappendmethod:
// provide the hierarchy. Orders is the root. OrderDetails
// and Customers are siblings at the next level
// and Products is a child of OrderDetails.
getMetaDataTree().setRoot((TreeNode) orders);
orders.append(Customers);
orders.append(OrderDetails);
//Since Products depends on OrderDetails:
orderDetails.append(products)To sum up, the append method places the meta data objects in their proper positions in the meta data tree. The same thing can be accomplished without coding if you use the
JCTreeDatacustomizer in an IDE.
2.3.1 Keeping Track of Rows
Now that the meta data has been defined the model can be given over to a grid such as JClass HiGrid, which will manage the display. Behind the scenes, the JClass DataSource has retrieved and cached a number of rows of each table. This number may be zero for any sub-table that has not yet been opened, but all the rows of the root table that match the query are cached. JClass DataSource needs to keep track of these rows, and to accomplish this in an efficient manner more than one strategy is employed.
The most important parameter that labels a row is called the bookmark. This
longinteger is guaranteed to uniquely label a row at any given time, but it is not guaranteed to be invariant. A row's bookmark most probably will change over time as a result of insert and delete operations on other rows. Other operations may cause a reassignment of bookmarks to existing rows. Thus, if you store a row's bookmark, you must ensure that you do not perform any of the operations that may change the bookmark in the interim before you use it again and expect that it refers to the same row. In fact, after bookmarks have been reassigned, an old bookmark may not refer to any row.While bookmarks are sufficient to label a row, efficient operation requires other ways of labeling them. A quantity called the row index is used to label each row of a given table sequentially, starting at zero. Obviously, these numbers are not unique as soon as there is more than one table in your application, but they do serve to help you to easily loop through the rows of a given table.
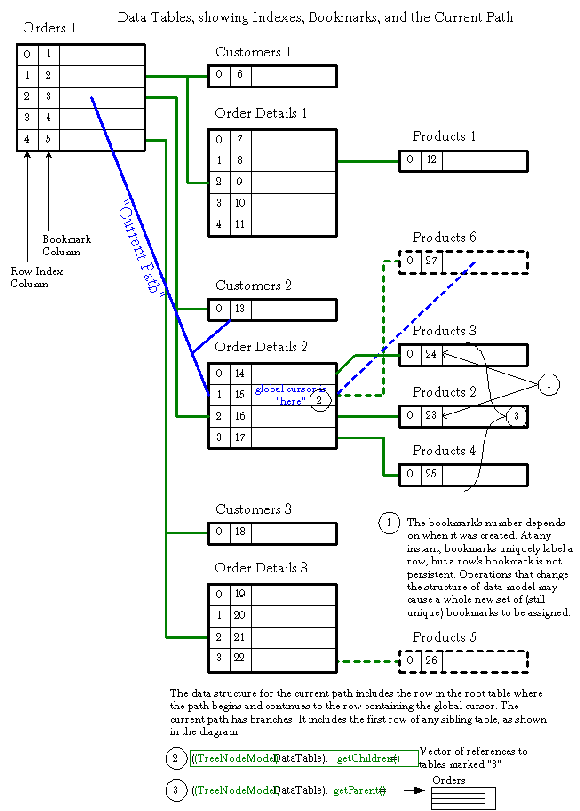
A global cursor keeps track of the cell containing the editor. This cell is selected and has focus. There is at all times one and only one active editor. Because data-bound components can be attached to any meta data level, a mechanism is required to allow that component to decide what data it should display depending on where the global cursor is positioned. A construct called the current path assists in this regard. As you follow this discussion, please refer to Figure 2.
Figure 2 : How rows are indexed.
Our example has the global cursor positioned on the row whose bookmark is 15 in the table we have called Order Details 2. This name serves to identify a table in the diagram but it is not a name that would appear anywhere in the Java code. It indicates that it was the second Order Details table created, perhaps as a result of a user clicking on row 3 of the root table, Orders, in a grid. Assume further that you have bound a text field component to one of the columns in the Products meta data. What information, if any, should the field display? In this case the choice is rather obvious: the text field should display the information contained in the chosen column of Products 6 rather than leaving the field blank simply because the user has not yet opened this level using the grid. In a less obvious case, what should be done if the Products 6 table contains more than one row? In this case, the current path points to the first row of the table, and to the first row of all dependent tables if they exist. Because of the possibility of using data-bound components, a current path must include branches such as the connection to Customers 2. Again, because an application could have added a data-bound component to the Customers level, JClass DataSource must be able to tell which particular piece of information to use when the field itself is not selected. Again in our example, there is only one customer per order so the choice of which row to use does not arise. In general, when there are a number of possibilities, the one with row index 0 is chosen.
What happens when an application containing a data-bound component at the Products level starts? From the point of view of the component, and taking a column in table Products as our example, the sequence is as follows. The component requests data. Products has no data in it as yet, so it asks Order Details to supply a reference. Since Order Details has no data, it asks Orders for a reference. Orders responds with its current row, which by default is the row whose index is 0. Order Details can now populate itself, and passes its default row index, again 0, for the table corresponding to row 0 of Orders, to Products. Products populates the referenced data table and the component receives its data. In this way a forward referencing policy is established and components always contain values, even at start up.
If the global cursor is somewhere down the hierarchy, back references are easy: just follow the tree back to its root. In the case where there are two tables at a level and the cursor is in one of them, the row whose index is 0 of the other table is deemed to be on the current path, so any component bound to that table would choose its value (or values) from the index 0 row.
Figure 3 shows some of the common ways of using bookmarks to navigate around the hierarchy. The color coding in this figure is the same as that in Figure 1. Some of the methods return references to tables, others return bookmarks and row indexes.
Figure 3 : Using bookmarks and row indexes.
If you have noticed that there are some capitalized names in the above examples in places where lower case method names are expected, it is because these capitalized names are used to indicate the class of object that is being talked about, not instances of that class. You must have an instance of the class to produce legal Java code.
Method
createTablein classcom.klg.jclass.datasource.BaseDataTablecreates and returns theDataTable, which corresponds to the specified row in the parent for the indicated childMetaDataobject.Methods
getAncestors,getParentBookmark,getAncestorBookmark,getRowIdentifier,getRowIndex,getRows, andgetMetaDataall return numeric data, except for the last which returns a reference to its own table.Method
getMetaDataTreereturns a reference to the root of theMetaDatatree.
2.4 Setting the Data Model
The data model may be set programmatically or through a customizer. Both methods are described here.
Setting Up an Unbound Data Model Programmatically
The
DataModel,MetaDataModel, andDataTableModelinterfaces define the structure that needs to be established no matter what kind of data source will eventually be used. Base classesTreeData,BaseMetaData, andBaseDataTableare available for use as implementations of these interfaces. The process of creating data tables begins with aDataModel, possibly by instantiating or subclassing theTreeDataclass. Normally, the data tables in JClass DataSource are derived from corresponding tables in a database, but that need not be the sole source. They can be created dynamically, as exemplified by the example program calledVectorData. This programmatic source data is used as an alternate in case there is a problem in connecting to the sample database.It serves to illustrate the origination of a data source. The class
public class VectorData extends TreeDataVectorDataitself extendsTreeData, so it functions as the data model:Array variables within this class are used to define the columns and their associated data types for the tables that are about to be created. After a data model is available, the next step is to create the meta data objects for the various levels that tables will occupy. The "bare" meta data objects are instantiated through a call to
BaseMetaData Orders = new BaseMetaData(this);BaseMetaData's constructor, giving the data model as a parameter. An example is the following line of code:The meta data objects must be structured by specifying their hierarchy. The example specifies a root table called Orders with two children called OrderDetails and Customer. Capturing this hierarchy reduces to adding the meta data objects to a tree. Since the
getMetaDataTree().setRoot((TreeNode) Orders);getMetaDataTreemethod inTreeDatais an implementation of the one named inDataModel, and returns aTreeModel, it can be used to set the Orders table as the root of the tree:The children are placed by appending them to the root:
Orders.append(OrderDetails);
Orders.append(Customers);The tables' relationships to one another have been set, but the tables themselves have no definition as of yet, let alone any content. Since column names and data types are available in arrays called
// set up columns for the Orders tableorders_columns[][]anddetails_columns[][], they are used to set up the columnnar structure of the tables as follows:
for (int i = 0; i < orders_columns.length; i++) {
BaseColumn column = new BaseColumn();
column.setColumnName(orders_columns[i][0]);
column.setMetaColumnTypeFromSqlType(getType(orders_columns[i][1]));
column.setColumnType(getType(orders_columns[i][1]));
Orders.addColumn(column);A similar block of code sets up the columnar structure of the OrderDetails table. Note that columns can be derived from
BaseColumn, which is an implementation of theColumnModelinterface.At this point the actual data table can be created using the constructor for a
VectorDataTable root = new VectorDataTable(Orders);BaseDataTableand passing aMetaDataModelas a parameter. SinceVectorDataTableis subclassed fromBaseDataTable, andOrdersis aBaseMetaDataobject and therefore implements theMetaDataModelinterface, the following code creates the root level of the data tree:
getDataTableTree().setRoot((TreeNodeModel) root);The values in the cells of a row are computed. The example merely fills them with random data by declaring an array called
root.addInternalRow(row);rowand generating data for each cell, that is, for each element of the array.BaseDataTablehas a method calledaddInternalRow(Object row)that does the job:The two sub-tables are instantiated by a call to the other form of
public VectorDataTable(MetaDataModel metaData, long parentRow) {BaseDataTable's constructor.
super(metaData, parentRow);
}In the example program, the tables are instantiated within a custom version of
createTable. This method is part of theDataTableModelinterface and is defined inBaseDataTable. It is overridden in the example'sVectorDataTableclass so that it can populate tables from array data generated within the program rather than by querying a database. To see how an unbound data table can be generated, checkexample.datasource.vector.VectorDataTable.javain the examples directory.
2.4.1 Query Basics
JClass DataSource has not been designed to create databases or their tables (for instance, by adding new columns to the database itself), although, technically, it is possible to do so. It is assumed that you have an existing database and you want to provide a hierarchical graphical interface for its tables and fields, perhaps adding summary columns of your own design. The contents of a database are examined and modified through the use of SQL's Data Manipulation Language (DML), whose basic statements are SELECT, INSERT, UPDATE, and DELETE. JClass DataSource parses an SQL statement into its clauses but it does not attempt to validate the clause itself. Instead, it passes the clauses on to the underlying database which will determine whether it can process the statement or not.
String query = " select *";
query += " from sales_order a, fin_code b";
query += " where a.fin_code_id = b.code";
query += " order by a.id asc";the
whereandorder byclauses will be passed on to the database without any check on their contents.You can use Prepared Statements. The interfaces
order_detail.setStatement("select * from sales_order_items where id = ?");java.sql.PreparedStatementandjava.sql.Connectionare used for this purpose. Consult thejava.sqlAPI for further information. You can use the question mark parameter (?) as a placeholder for joins. The question mark is a placeholder for the field that will be supplied when the statements are executed. An example of the use of the question mark placeholder is as follows:Here, a matching
idfield in the parent table is used in the comparison.
2.4.2 Specify the Tables and Fields to be Accessed at Each Level
If you are using the JDBC but not using an IDE, you must create instances of the
MetaDataclass for each level programmatically, specifying both the table and the SQL query to be used. One form of the constructor is required to instantiate the root table. The database query is passed as one of its arguments. All other levels are instantiated using a form that names the instance of theHiGrid(or other GUI) being used, the table name, and the database connection object. The query String is passed separately, using a method calledsetStatement.Other parameters can be set, such as descriptive statements for the table captions, header and footers, columns containing aggregate data, and so on.
2.4.3 Set the Commit Policy to be Used when Updating the Database
You have control over when changes should be committed: you can choose a commit policy that ranges from allowing the end-user to decide when to commit the changes, waiting until the selected row changes (waiting until the selected group changes), or giving your application control over when to commit the changes.
2.4.4 Store Result Sets from Queries
Database queries may result in a varying amount of data, anything from the entire table on which the query was based to a null result in the case where the database returned nothing at all that matched the query. If these results are to be displayed in a grid, the result set must be stored. The result sets for each query that you define at each level are stored separately.
2.4.5 The Data Bean
Use JClass DataSource's
JCDatawhen you want to present a single level of data to the end-user. In effect, this JavaBean functions as a table whose rows are retrieved from the chosen database and whose columns are the fields that you select from the table (or tables, if two or more are joined).What follows is an example of using the Data Bean in the BeanBox. We'll show all the steps in setting up the database access, and all the way through to connecting to a JClass HiGrid to display the query's result set.
- Once you have installed your JAR file in its proper location, which in the case of the BeanBox is your bdk/jars directory, you should see the JavaBeans called
JCData,JCTreeData, and the Swing-based data bound componentsDSdbJCompoBox, and so on, as well asDSdbJNavigator, JClass DataSource's data navigator.Figure 4 : The Bean Development Kit's ToolBox, containing HiGrid's Beans.
- Click on JCData and move the mouse pointer to the BeanBox, where it turns into a crosshair. Click once more and the outline of the data JavaBean appears. The data Bean has a property sheet like the one shown next.
Figure 5 : JCData's property sheet.
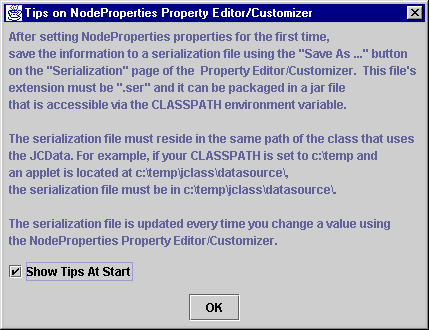
- Click on the area to the right of the label nodeProperties to access its main custom editor. A modal dialog appears, reminding you about ensuring that the serialization file which is about to be created is on your CLASSPATH.
Figure 6 : A reminder about creating a serialization file.
- On the Node Properties Editor, click Open if you have a previously-saved serialization file that you want to use, otherwise click Save As. Type a filename in the file dialog, or accept the default name, and click Save.
- Click the NodePropertiesEditor's Data Model tab.
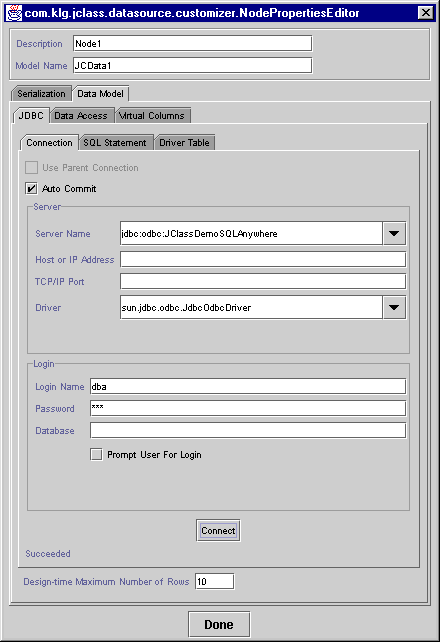
- There are two nested tabbed dialog panels. The JDBC tab is selected, causing the Connection tab panel to be visible. The reason for this choice is that it is assumed that the first thing you want to do is to specify the database connection. The other tabs are Data Source Type, Data Access, Virtual Columns and IDE. They will be discussed shortly.
There are text fields for the server name, host or IP address, TCP/IP port, and Driver, along with a group of fields that may be required to log on to a database that requires a user name and a password. Fill in as many of these as are required for your particular situation.
Figure 7 : Fill in these fields to connect to your chosen database.
For reference, the other tabs permit you to specify the driver table and the type of data access that will be allowed.
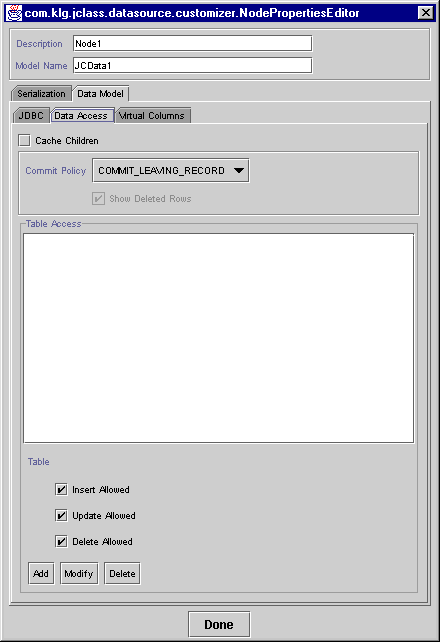
Figure 8 : The Data Access tab.
- The Data Access tab allows you to set a commit policy and an edit policy. Three checkboxes control editing permissions: Insert Allowed, Update Allowed, and Delete Allowed. You can also choose one of three commit policies from a drop-down menu:
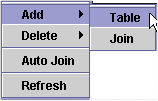
COMMIT_LEAVING_RECORD,COMMIT_LEAVING_ANCESTOR, orCOMMIT_MANUALLY.- Return to the JDBC tab and click on the SQL Statement tab. This exposes the tab containing two scroll panes, as shown in Figure 9. The top scroll pane is for placing the smaller scroll panes that represent the tables from your database. The first step in choosing a table is to right-click on the top scroll pane, or click on the button labeled Add Table. Click Add in the popup menu that appears.
Figure 9 : The SQL Statement tab.
The database is accessed and a list of its tables is retrieved.
Figure 10 : The popup menu for adding tables.
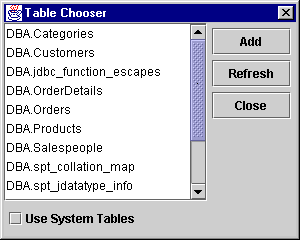
- A new dialog will appear, allowing you to select a table from the list of retrieved database tables. Choose a table and click Add.
Figure 11 : The Table Chooser dialog.
You can choose more than one table if you wish. The result will be a grouping of the two tables, but as of yet no columns or joins have been specified. For this operation to be meaningful, it is likely that you will have to choose the tables whose data you will be accessing, then specify the names of the common fields in each table.
Each data table scroll pane has a label that identifies it. The scroll area contains the list of fields for that table. You build the query by selecting a field in this list and choosing Add Selected Columns. This action causes the field name to be added to the select statement in the SQL Statement scroll pane.
The query in the SQL Statement pane contains an editable text frame. You can refine the query by adding any clause that the database language supports.
A sample, containing two tables, is shown in Figure 12.
Important: Click the Set button to store the query. If you omit this step and close the SQL Statement tab, all the settings you made will be cleared.
It's also important to realize that the SQL Statement panel has helped you build a query simply by making the appropriate choices in the customizer, although you can type query statements into the text area of the SQL statement panel. Your IDE takes it from there and builds the necessary code.
Figure 12 : The SQL Statement panel.
The setup of the JCData is complete. What remains is to connect this JavaBean to a visual component so that the result set can be displayed. We'll carry on with this example by actually displaying the result of our query.
- Select JCHiGrid in the ToolBox and place an instance on the BeanBox.
- Resize it so that it is big enough to hold most of the cells in five or six rows.
- In the BeanBox, highlight the JCData and choose Edit > Events > dataModel > dataModelCreated. A line in the form of a rubber band extends from the JCData component to the tip of the mouse pointer.
- Move the tip of the mouse pointer anywhere along the edge of the
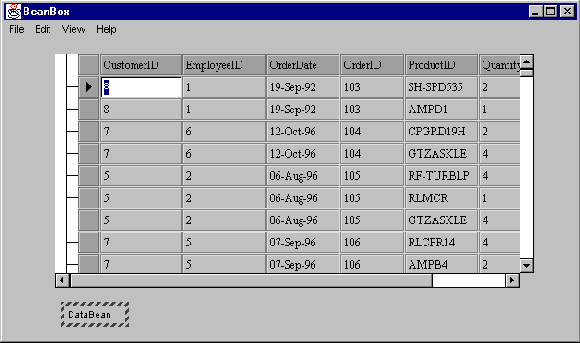
HiGridBeancomponent, click and again choose dataModelCreated from the popup menu that appears.- Your grid fills with the retrieved data, as shown in Figure 13.
Figure 13 : A database table as it appears in the BeanBox.
2.5 JClass DataSource's Main Classes and Interfaces
A
TreeModelinterface defines the methods that implement a generic interface for a tree hierarchy. The tree interface is used for organizing the meta data and the actual data for the JClass DataSource.The
DataModelis the data interface for the JClass DataSource. An implementation of this interface will be passed to the data source. All data for the DataSource is maintained and manipulated in this data model through its sub-interfaces. This data model requires the implementation of two tree models, one for describing the relationships of the hierarchical data (MetaDataModel) and one for the actual data (DataTableModel).The
TreeNodeModelis the interface for nodes of theTreeModel.BaseDataTable root = new BaseDataTable(rootMetaData);
BaseDataTableprovides a default implementation ofDataTableModelandDataTableAbstractionLayerinterfaces. Instances of this class provide basic storage, retrieval, and manipulation operations on data rows. This class can be used without extending it. In this case you must create and populate rows manually. For example,
data_tree.setRoot((TreeNode) root);
int row1 = root.addRow();
root.updateCell(row1, column1, value1);
root.updateCell(row1, column2, value2); // etc. ...Extensions of this class, for example the JClass DataSource JDBC implementation, automatically create/populate data tables based on data returned from datasource queries. In the case of IDE-specific implementations, they extend this class and override the data storage and retrieval mechanisms. Users wishing to extend this class should look at overriding some or all of the methods defined in the
DataTableAbstractionLayerinterface. These are the methods most likely to need overriding. Each instance of this class has its own cursor which can be navigated independently of theDataModel's global cursor. Only the global cursor (controlled byDataModel.moveToRow) causes commits to occur when the current row is changed. The navigation methods here do not cause the global cursor to change, only this table's private cursor.Figure 14 : Major classes and interfaces for the Data Model.
Commit Policy
Updating a database is a two step process. First, a cell or group of cells is edited, then the edits are confirmed by committing them to the database.
COMMIT_MANUALLY - Requires a click on the pencil icon (or the X icon), or you can select any of Update All, Update Current, Update Selected from the pop-up menu.
COMMIT_LEAVING_RECORD - Commits changes to a row as soon as the cursor moves to a different bookmark.
COMMIT_LEAVING_ANCESTOR - Does not commit until a sub-tree is accessed which has a different parent-level bookmark than the previous one (see
DataTableModel.getMasterRow()). By convention, setting the root-levelMetaDataobject toCOMMIT_LEAVING_ANCESTORis equivalent to setting it toCOMMIT_MANUALLY.
2.6 Examples
Row Nodes
It often helps in simplifying your code if you assign names to rows. Method
String x = rowNode.getDataTableModel().getMetaData().getDescription();setDescriptionassigns any name you choose to a row node. This name can then be retrieved withgetDescription. SincegetDescriptionrequires an object of typeMetaDataModel, a possible invocation would be:You can find the row node associated with an event as follows:
ValidateEvent event = e.getValidateEvent();
RowNode rowNode = e.getRowNode();
getRowNodereturns the row node of the row on which the event occurred.
2.6.1 Useful Classes and Methods as Demonstrated by Code Snippets
The following sections demonstrate some common tasks by using code snippets.
For most applications, you will need to perform the following steps:
- Connect to a database
- Set commit policies
- Specify joins on tables using single or multiple keys
- Refresh data structures after the data has been modified (including the insertion of a new row or deletion of a row)
- Inspect bookmarks and column identifiers
- Sort data
- Programmatically move through the retrieved-record data structure and possibly calculate totals or other summary information
- Cancel some or all of a group of pending changes
- Inspect column identifiers
- Recover from operations that attempt to violate database integrity.
Connecting to a Database via a JDBC-ODBC Bridge and Setting the Top-level Query
Use the
DataTableConnection c = new DataTableConnection(DataTableConnectionconstructor to instantiate a new connection, then use the root form of theMetaDataconstructor to set the top-level query.
"sun.jdbc.odbc.JdbcOdbcDriver", // driver
"jdbc:odbc:GridDemo", // url
"Admin", // user
"", // password
null); // database
String query_string = "SELECT * FROM myTable";
MetaData root_meta_data = MetaData(data_model,c, query_string);Joining Tables
Joining tables involves creating a new node that names its parent using the second form of the
private MetaData createDetailChild(InsertData link, MetaData par, DataTableConnection c)MetaDataconstructor, building a query statement, and setting it on the node, then issuing the join command or commands. Here, two joins are indicated.
{
try
{
// Link the customer table to the SalesOrder table
MetaData node = new MetaData(link, par,c);
node.setStatement("SELECT * FROM OrderDetail WHERE order_id = ? AND store_id = ?");
node.joinOnParentColumn("id","order_id");
node.joinOnParentColumn("store_id","store_id");
node.open();
node.setColumnTableRelations("OrderDetail", new String[] {"*"});
return node;
}
catch (DataModelException e)
{
ExceptionDump.dump("Creating OrderDetail Child Table", e);
System.exit(0);
}
return null;
}Refreshing Tables
This example shows how you might construct a method that refreshes a table. The data types of the variables can be inferred from the casts.
public void refreshStructure()
{
this.meta_tree = (TreeModel) this.data_model.getMetaDataTree();
this.meta_data_model = (MetaDataModel) this.meta_tree.getRoot();
this.data_tree = (TreeModel) this.data_model.getDataTableTree();
this.data_table_model = (DataTableModel) this.data_tree.getRoot();
}Setting Permissions
This example shows how to set modification permissions programmatically.
public void setPermissions(String table,boolean ia,boolean da,boolean ua)
{
this.meta_data_model.setInsertAllowed(table,ia);
this.meta_data_model.setDeleteAllowed(table,da);
this.meta_data_model.setUpdateAllowed(table,ua);
}
2.7 Binding the data to the source via JDBC
In order to bind the data, you must first connect to a database using the DataSource customizer. This is described in Making a Connection to a Database, in Chapter 4.
Accomplishing the same thing programmatically involves these steps:
- Create an instance of a
DataModelwhich will be passed to the connection method, so the class in which the connection parameters and the query are formed becomes the first parameter in the call toMetaData.- Next, form a
DataTableConnectionobject, and a query String.- Once the connection is made, and the query is passed to the database, use the root constructor
MetaData(DataModel, DataTableConnection, String).- If sub-tables are required, they are constructed using
MetaData(DataModel, MetaData, DataTableConnection). In this form of the constructor, theMetaDataobject refers to the parent table.Note: The query String must satisfy the database language requirements. Generally speaking, SQL-92 should be used.
2.7.1 Getting Table Names
Some databases have trouble sorting out the proper association when two or more tables are used at the same grid level. In these cases,
ColumnModelmethodgetTableNamefails to return the necessary information about column names. In this case, you must supply the proper join or update statement yourself. A helper method namedsetColumnTableRelationsis available.Method
Orders.setColumnTableRelations("SalesOrder", new String[] {"id","store_id","cust_id","ship_via","purchase_order_number", "order_date","order_total"});setColumnTableRelationsexplicitly sets the relationships between tables and columns. If introspection fails to determine the association between tables and their columns (when there is more than one table to a level), or you wish to override the associations, say to exclude a column in the update statement, use this method. This method must be called for each table. For example, ifSalesOrderandStoreare joined in a one-to-one relationship for a level, these would be the necessary calls. In this example theMetaDataobject is calledOrders.
Orders.setColumnTableRelations("Store", new String[] {"store_store_id","address","phone_number","name"});For a single table on a level the call would be,
Customer.setColumnTableRelations("Customer", new String[] {"*"});Note: The "*" means all columns are from the Customer table.
2.7.2 Ambiguous Column Names
The JClass data model requires that if a column or field in one table has the same name as that in another table, the two must be capable of being meaningfully joined. That is, the two names must refer to the same logical property of some entity. Since you cannot always control the various field names in database tables, there is an alias mechanism that allows you to rename dissimilar fields that happen to have the same name. Assume that a SalesOrder table has an id field, and a table named Store also has a field called id. These keys respectively refer to a sales order reference number and the identification number for a store. If you wish to form a query in which both tables are mentioned, and the id field of both is to be selected, you provide an alias for one of the fields in the query statement. Its syntax goes like this:
SELECT SalesOrder.id, ... other SalesOrder field names ... , Store.id AS store_alias_id, ... other Store fieldsNow that Store.id has an alias, it is used in place of the actual table name and causes no problem. Just remember the rule: you can't have identical column names if they mean different things.
2.8 The Data "Control" Components
The Data Navigator Bean. This GUI component comes in two flavors,
DSdbNavigatorfor AWT andDSdbJNavigatorfor Swing. They allow you to navigate through the database records. Both have the same behavior, which is described in The Navigator and its Functions, in Chapter 5.
Figure 15 : The Data Navigator.
2.9 Custom Implementations
2.9.1 Unbound Data
There may be times when you need to compute results that cannot be obtained through SQL queries. Typically these situations arise when the results depend on a computation that involves more than one column, or if it requires a function that is not supported by one of the Aggregate classes. It has become customary to refer to this type of generated data as "unbound data," and we will use the term this way. You can provide added functionality to your application with this flexible technique by adding a separate class that manages the required callbacks. An example follows.
Imagine that the requirement is for a column containing a calculation that requires extra verification logic, or some other calculation not covered by the existing aggregate types. You can extend
AggregateAlland override itscalculatemethod to provide the custom calculation.See
SummaryUnboundDataExamplefor the complete listing. It shows how to locate the node containing the fields you want to work with and add a new summary column containing the derived quantity. An outline of the procedure is given next.In your main class, append a new summary column to the node's footer:
SummaryColumn column = new SummaryColumn("Order Total Less Tax: ");
orderDetailFooterMetaData.appendColumn(column);Provide parameters in the summary column's constructor like these when you want unbound data:
column = new SummaryColumn(orderDetailMetaData,
"jclass.higrid.examples.OrderDetailTotalAmount",
SummaryColumn.COLUMN_TYPE_UNBOUND,
SummaryColumn.AGGREGATE_TYPE_NONE,
MetaDataModel.TYPE_DOUBLE);
orderDetailFooterMetaData.appendColumn(column);
orderDetailFooterFormat.setShowing(true);The second parameter names the class that defines the new calculation, which is presented next. Note that its constructor calls the base class to provide the required initialization.
package jclass.higrid.examples;OrderDetailTotalAmountprovides the logic for calculations on each row andAggregateAllsums them to a group total.
import jclass.higrid.AggregateAll;
import jclass.higrid.RowNode;
/**
* Calculates the order detail total amount.
*/
public class OrderDetailTotalAmount extends AggregateAll {
public OrderDetailTotalAmount() {
super();
}
/**
* Perform the aggregation.
*
* @param rowNode The row node.
*/
public void calculate(RowNode rowNode) {
if (isSameMetaID(rowNode)) {
Object quantity = getRowNodeResultData(rowNode, "Quantity");
Object unitPrice = getRowNodeResultData(rowNode, "UnitPrice");
if (quantity != null && unitPrice != null) {
double amount = getDoubleValue(quantity) *
getDoubleValue(unitPrice);
addValue((Object) new Double(amount));
}
}
}
}
2.9.2 Batching HiGrid Updates
You can control the frequency at which updates occur. Normally, you want the grid to be repainted immediately after a change is made or a property is set. To make several changes to a grid before causing a repaint, set the
setBatchedproperty ofHiGridobject totrue. Property changes do not cause a repaint until asetBatched(false)command is issued.Thus, when initializing an object, or performing a number of property changes at one time, you can begin and end the section as follows.
grid = new HiGrid();
grid.setBatched(true);
grid.setDataModel(new MyDataSource());
grid.setBatched(false);Setting a new data model may cause the grid to request numerous repaints, but these are prevented by sandwiching the command between the two
setBatchedcommands.
2.10 Use of Customizers to Specify the Connection to the JDBC
If you have previously made a connection to your chosen database and have saved the information in a serialization file, then all you have to do is launch the customizer and specify the serialization file to reload. The following two figures show the dialogs for the single data level (in
JCData) and for the hierarchicalJCTreeData. In either case, you type in the filename or use the Load... button to choose it in a file dialog.
2.11 Classes and Methods of JClass DataSource
The following sections describe many of the classes and methods that application programmers find useful.
2.11.1 MetaDataModel
Use the constants in the following table when you want to map a JDBC data type to a Java type. These are the types that are returned. These constants are defined in
jclass.datasource.MetaDataModel.
2.11.2 Data Model
This is the data interface for the JClass DataSource. An implementation of this interface will be passed to the class using the data source. All data for the data source is maintained and manipulated in this data model through its sub-interfaces. This data model requires the implementation of two tree models, one for describing the relationships of the hierarchical data (
MetaDataModel) and one for the actual data (DataTableModel).
BaseDataTableis an abstract implementation of the methods and properties common to various implementations of theDataTableModel. This class must be extended to concretely implement those methods not implemented here, which are all of the methods in theDataTableAbstractionLayer.The object that actually holds the data retrieved from the database is
DataTable. Its implementation is specific to the type of data binding that different sources provide, so its implementation is different in each of the supported IDEs. The following discussion assumes a direct connection to JDBC rather than via an IDE.public class DataTable extends BaseDataTable
DataTablecontains a copy of the data returned in a JDBC result table, which will be copied into one of these result tables so the data can be cached. Rows can then be added, deleted or updated through thisDataTable. All operations can access data through row/columnidxToBookmarkMaprather than indexes. This facilitates sorting of rows and/or columns.
|
|